Those of you reading this might also be interested in two_percent, which is a fork of skim, which in turn is a Rust implementation of fzf. two_percent is faster, more efficient and uses less memory than fzf, which is especially noticeable with large inputs.
- 5 Posts
- 21 Comments
Joined 1 year ago
Cake day: June 10th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
No need to hop around for the same thing.
It’s not really the same thing. EndeavourOS is basically vanilla Arch + a few branding packages. CachyOS is an opionated Arch with optimised packages.
You still have the option to select the DE and the packages you want to install - just like EndeavourOS - but what sets Cachy apart is the optimisations. For starters, they have multiple custom kernel options, with the BORE scheduler (and a few others), LTO options etc. Then they also have packages compiled for the x86-64-v3 and v4 architectures for better performance.
Of course, you could also just use Arch (or EndeavourOS) and install the x86-64-v3/v4 packages yourself from ALHP (or even the Cachy repos), and you can even manually install the Cachy kernel or a similar optimised one like Xanmod. But you don’t get the custom configs / opinionated stuff. Which you many actually not want as a veteran user. But if you’re a newbie, then having those opinionated configs isn’t such a bad idea, especially if you decide to just get a WM instead of a DE.
I’ve been thru all of the above scenarios, depending on the situation. My homelab is vanilla Arch but with packages from the Cachy repo. I’ve also got a pure Cachy install on my gaming desktop just because I was feeling lazy and just wanted an optimised install quickly. They also have a gaming meta package that installs Steam and all the necessary 32-bit libs and stuff, which is nice.
Then there’s Cachy Browser, which is a fork of LibreWolf with performance optimisations (kinda similar to Mercury browser, except Mercury isn’t MARCH optimised).
As for support, their Discord is pretty active, you can actually chat with the developers directly, and they’re pretty friendly (and this includes Piotr Gorski, the main dev, and firelzrd - the person behind the BORE scheduler). Chatting with them, I find the quality of technical discussions a LOT higher than the Arch Discord, which is very off-topic and spammy most of the time.
Also, I liked their response to Arch changes and incidents. When Arch made the recent mkinitcpio changes, their made a very thorough announcement with the exact steps you needed to take (which was far more detailed than the official Arch announcement). Also, when the xz backdoor happened, they updated their repos to fix it even before Arch did.
I’ve also interacted with the devs pesonally with various technical topics - such as CFLAG and MARCH optimisations, performance benchmarking etc, and it seems like they definitely know their stuff.
So I’ve full confidence in their technical ability, and I’m happy to recommend the distro for folks interested in performance tuning.
cc: @governorkeagan@lemdro.id
Others here have already given you some good overviews, so instead I’ll expand a bit more on the compilation part of your question.
As you know, computers are digital devices - that means they work on a binary system, using 1s and 0s. But what does this actually mean?
Logically, a 0 represents “off” and 1 means “on”. At the electronics level, 0s may be represented by a low voltage signal (typically between 0-0.5V) and 1s are represented by a high voltage signal (typically between 2.7-5V). Note that the actual voltage levels, or what is used to representation a bit, may vary depending on the system. For instance, traditional hard drives use magnetic regions on the surface of a platter to represent these 1s and 0s - if the region is magnetized with the north pole facing up, it represents a 1. If the south pole is facing up, it represents a 0. SSDs, which employ flash memory, uses cells which can trap electrons, where a charged state represents a 0 and discharged state represents a 1.
Why is all this relevant you ask?
Because at the heart of a computer, or any “digital” device - and what sets apart a digital device from any random electrical equipment - is transistors. They are tiny semiconductor components, that can amplify a signal, or act as a switch.

A voltage or current applied to one pair of the transistor’s terminals controls the current through another pair of terminals. This resultant output represents a binary bit: it’s a “1” if current passes through, or a “0” if current doesn’t pass through. By connecting a few transistors together, you can form logic gates that can perform simple math like addition and multiplication. Connect a bunch of those and you can perform more/complex math. Connect thousands or more of those and you get a CPU. The first Intel CPU, the Intel 4004, consisted of 2,300 transistors. A modern CPU that you may find in your PC consists of hundreds of billions of transistors. Special CPUs used for machine learning etc may even contain trillions of transistors!
Now to pass on information and commands to these digital systems, we need to convert our human numbers and language to binary (1s and 0s), because deep down that’s the language they understand. For instance, in the word “Hi”, “H”, in binary, using the ASCII system, is converted to 01001000 and the letter “i” would be 01101001. For programmers, working on binary would be quite tedious to work with, so we came up with a shortform - the hexadecimal system - to represent these binary bytes. So in hex, “Hi” would be represented as
48 69, and “Hi World” would be48 69 20 57 6F 72 6C 64. This makes it a lot easier to work with, when we are debugging programs using a hex editor.Now suppose we have a program that prints “Hi World” to the screen, in the compiled machine language format, it may look like this (in a hex editor):
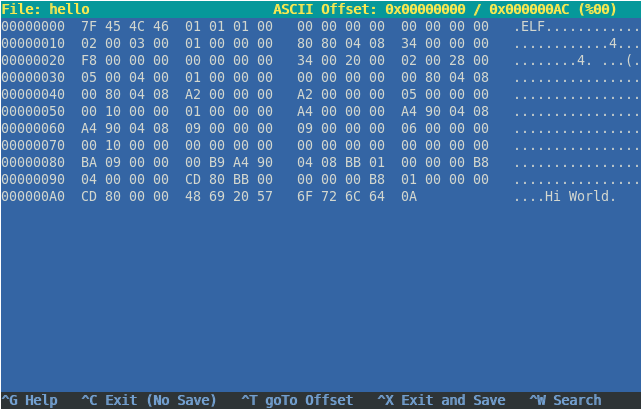
As you can see, the middle column contains a bunch of hex numbers, which is basically a mix of instructions (“hey CPU, print this message”) and data (“Hi World”).
Now although the hex code is easier for us humans to work with compared to binary, it’s still quite tedious - which is why we have programming languages, which allows us to write programs which we humans can easily understand.
If we were to use Assembly language as an example - a language which is close to machine language - it would look like this:
SECTION .data msg: db "Hi World",10 len: equ $-msg SECTION .text global main main: mov edx,len mov ecx,msg mov ebx,1 mov eax,4 int 0x80 mov ebx,0 mov eax,1 int 0x80As you can see, the above code is still pretty hard to understand and tedious to work with. Which is why we’ve invented high-level programming languages, such as C, C++ etc.
So if we rewrite this code in the C language, it would look like this:
#include <stdio.h> int main() { printf ("Hi World\n"); return 0; }As you can see, that’s much more easier to understand than assembly, and takes less work to type! But now we have a problem - that is, our CPU cannot understand this code. So we’ll need to convert it into machine language - and this is what we call compiling.
Using the previous assembly language example, we can compile our assembly code (in the file
hello.asm), using the following (simplified) commands:$ nasm -f elf hello.asm $ gcc -o hello hello.oCompilation is actually is a multi-step process, and may involve multiple tools, depending on the language/compilers we use. In our example, we’re using the
nasmassembler, which first parses and converts assembly instructions (inhello.asm) into machine code, handling symbolic names and generating an object file (hello.o) with binary code, memory addresses and other instructions. The linker (gcc) then merges the object files (if there are multiple files), resolves symbol references, and arranges the data and instructions, according to the Linux ELF format. This results in a single binary executable (hello) that contains all necessary binary code and metadata for execution on Linux.If you understand assembly language, you can see how our instructions get converted, using a hex viewer:

So when you run this executable using
./hello, the instructions and data, in the form of machine code, will be passed on to the CPU by the operating system, which will then execute it and eventually printHi Worldto the screen.Now naturally, users don’t want to do this tedious compilation process themselves, also, some programmers/companies may not want to reveal their code - so most users never look at the code, and just use the binary programs directly.
In the Linux/opensource world, we have the concept of FOSS (free software), which encourages sharing of source code, so that programmers all around the world can benefit from each other, build upon, and improve the code - which is how Linux grew to where it is today, thanks to the sharing and collaboration of code by thousands of developers across the world. Which is why most programs for Linux are available to download in both binary as well as source code formats (with the source code typically available on a git repository like github, or as a single compressed archive (.tar.gz)).
But when a particular program isn’t available in a binary format, you’ll need to compile it from the source code. Doing this is a pretty common practice for projects that are still in-development - say you want to run the latest Mesa graphics driver, which may contain bug fixes or some performance improvements that you’re interested in - you would then download the source code and compile it yourself.
Another scenario is maybe you might want a program to be optimised specifically for your CPU for the best performance - in which case, you would compile the code yourself, instead of using a generic binary provided by the programmer. And some Linux distributions, such as CachyOS, provide multiple versions of such pre-optimized binaries, so that you don’t need to compile it yourself. So if you’re interested in performance, look into the topic of CPU microarchitectures and CFLAGS.
Sources for examples above: http://timelessname.com/elfbin/
This shouldn’t even be a question lol. Even if you aren’t worried about theft, encryption has a nice bonus: you don’t have to worry about secure erasing your drives when you want to get rid of them. I mean, sure it’s not that big of a deal to wipe a drive, but sometimes you’re unable to do so - for instance, the drive could fail and you may not be able to do the wipe. So you end up getting rid of the drive as-is, but an opportunist could get a hold of that drive and attempt to repair it and recover your data. Or maybe the drive fails, but it’s still under warranty and you want to RMA it - with encryption on, you don’t have to worry about some random accessing your data.

First of all, I’m not the author of the article, so you’re barking up the wrong tree.
You’re using the unstable channel.
That doesn’t matter in the big scheme of things - it doesn’t solve the fundamental issue of slow security updates.
You could literally build it on your own, or patch your own change without having to wait - all you have to do is update the SHA256 hash and the tag/commit hash.
Do you seriously expect people to do that every time there’s a security update? Especially considering how large the ecosystem is? And what if someone wasn’t aware of the issue, do you really expect people to be across every single vulnerability across the hundreds or thousands of OSS projects that may be tied to the packages you’ve got on your machine?
The rest of your points also assume that the older packages don’t have a vulnerability. The point of this post isn’t really about the xz backdoor, but to highlight the issue of slow security updates.
If you’re not using Nix the way it is intended to be, it is on you. Your over-reliance on Hydra is not the fault of Nix in any way.
Citation needed. I’ve never seen the Nix developers state that in any official capacity.

 1·8 months ago
1·8 months agoI have a Zen 2, Zen 3+ and a Zen 4 system and they all work well very with various Linux distros (Arch, Fedora) and recent kernels.
It’s very likely that your bug is specific to early Ryzen CPUs/chipsets. A couple of folks on those reports mentioned their issues went away after a motherboard/BIOS upgrade. So I think you’ll be fine if you went for a more recent AMD CPU+mobo.
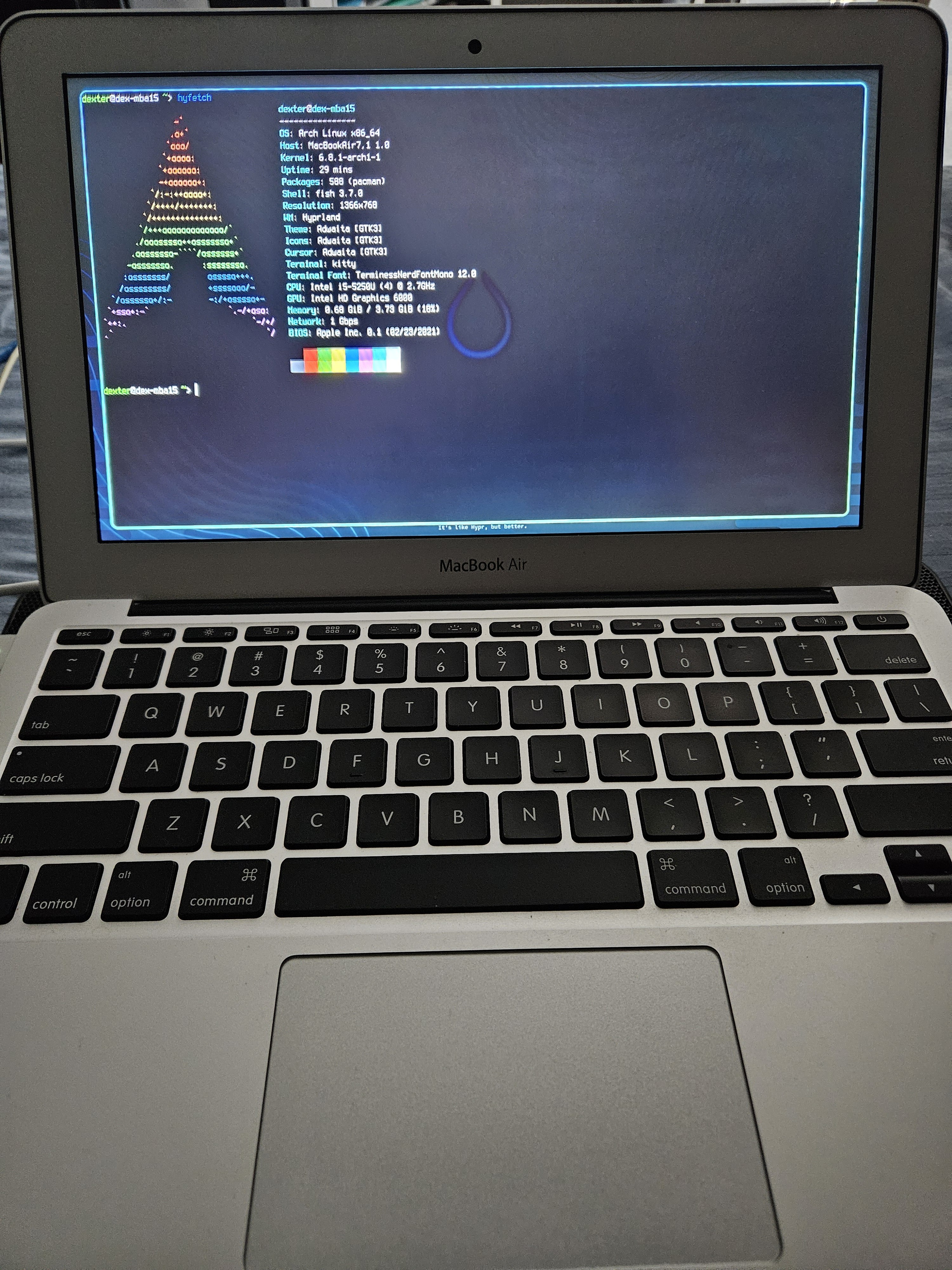
And the ones who install Arch on a MacBook need extra special therapy.
This is my my phone running Debian with XFCE:

matching other programs and platforms
Actually,
Ctrl+Cis the interrupt hotkey for pretty much every CLI app/terminal on every platform. Try it within the Command Prompt/PowerShell/Windows Terminal, or the macOS terminal - they’ll all behave the same.The use of
Ctrl+Cas an interrupt/termination signal has a very long history even predating the old UNIX days and DEC - it goes back to the days of early telecommunications, where control characters were used for controlling the follow of data through telecommunication lines. These control characters, along with regular characters, were transmitted by being encoded in binary, and this encoding scheme was defined by ASCII (American Stanard Code for Information Interchange), published in 1963.In ASCII, the control character
ETX(meaning end-of-text; represented by the hex code 0x03) was used to indicate “this segment of input is over”, or “stop the current processing”.Now what does all this have to do with with
Ctrl+Cyou ask?For that, you’ll need to go back to the days of early keyboards. Keyboards back then generated ASCII codes directly, and when a modifier key (Ctrl/Shift/Meta) on a keyboard was pressed in combination with another key, it modified the signal sent by the keyboard to produce a control character.
Specifically, pressing
Ctrlwith a letter key made the keyboard clear (set to zero) the upper three bits of the binary code of the letter, thus effectively mapping the letter keys to control characters (0x00 - 0x1F: the first 32 characters on the ASCII table).- The ASCII code for ‘C’ is 0x43 (binary 01000011).
- Pressing
Ctrl+Cclears the upper three bits, resulting in 00000011, which is 0x03 in hex.
And would you look at that, 0x03 is the code which represents the control character
ETX.The use of
ETXto interrupt a program in digital computers was first adopted by the TOPS-10 OS, which ran on DEC’s PDP-10 computer, back in the late 60s. It’s successor, TOPS-20 also included it, followed by the RSX-11 (on the PDP-11), and VMS (on the VAX-11).RSX-11 was a very influential OS, created by a team that included David Cutler. It influenced the design of several OSes that followed, such as VMS and Windows NT. Cutler later moved to Microsoft and became the father of Windows NT. Early NT did not include a GUI, so it was natural to adopt existing terminal operation standards, including the use of
ETX. In fact, NT’s internals were so similar to VMS that a lawsuit was in the works, but instead, MS agreed to pay off DEC millions of $$$.Also, when UNIX first came out (1969), it ran on DEC hardware, and so they followed the tradition of using the
ETXsignal to stop programs. This convention flowed to BSD (1978) which was based on UNIX, and NeXTSTEP (1989), which was based on BSD. NeXTSTEP was developed by NeXT Computers, which was founded by Steve Jobs… and the rest is history.Therefore,
Ctrl+Cis something that’s deeply rooted in history. You don’t just simply change something like that. Sure, you may be able to remap the keybindings, but it’s actually hardcoded into many programs so you’ll run into inconsistencies - that is, if you used the standard remapping tools built into GNOME/KDE etc.If you want to truly remap Ctrl+C, you’ll want to do so at a lower level (evdev layer) so that it’s not intercepted by other programs, eg using tools like evremap or keyd. But even then, it’s not guaranteed to work everywhere, for instance, if you’re inside a VM or using a different OS, or in a remote session. So it’s best to remap the keys at the keyboard layer itself, which is possible on many popular mechanical keyboards using customisable firmware like QMK/VIA.
If you were looking for answers to such questions 10 years ago, your best resource for finding a thorough, expert-informed response likely would have been one of the most interesting and longest-lasting corners of the internet: Quora.
I disagree, the best place for such answers used to be Reddit, and Stack Exchange for the techy stuff. Quora always felt like cancer for some reason and I never really used it.
There’s a Dolphin plugin for this: https://github.com/Nyre221/dolphin-quick-view

 0·10 months ago
0·10 months agoThat’s not a standard Windows prompt, looks like some third-party application is intercepting the call.
Check the registry:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Image File Execution Options- for a key named taskmgr.exe. If it exists, see if the taskmgr.exe key has a value called Debugger. If so, delete the Debugger value, or rename the taskmgr.exe key to e.g. taskmgr.exe.old.Then try launching Task Manager again.
If there’s nothing in the registry, you could monitor the process tree in Process Explorer and watch what happens when you execute taskmgr.exe. You could also use Process Monitor if you want to dig deeper and find out exactly what’s happening - you can filter out Microsoft processes to make it easier to see all thirdparty software interactions.
You should check out Nix the package manager, which is an even better option than Distrobox if you want to install stuff independently of your distro’s packaging system. The biggest advantage of using Nix is that there’s no container layer, so you’re running the binaries directly on your host OS - this means that the binary can have full access to system resources, which is handy if you need to run one of those apps with root privileges (try running a Distrobox exported app with
sudo- it won’t work). Or say you want to install something like a terminal emulator - it’s not exactly practical to install it inside Distrobox, because now every time you run the terminal, you’d be viewing at your system from inside the container, which can makes things pretty messy.Another advantage of Nix is that because you’re dealing with actual binaries and not just a shim script, it can handle command line arguments properly and also handle things like stdin/stdout properly. In fact there’s a bug right now with the way Distrobox export handles command line parameters, where it eats some of the parameters so your exported program may not work correctly. I had this issue with a Distrobox export of freerdp and raised an issue for it, but it still hasn’t been fixed. So until this is fixed, I’d advise staying away from running distrobox exported stuff, unless you’re using it for only simple apps/workflows.
Also, you don’t have the hassle of having to maintain/update the Arch or whatever OS is installed inside your containers.
Finally, with Nix you can easily roll back your transactions or switch between multiple versions of the apps - all of which takes place instantly, because all it’s doing is switching the symlinks in the Nix store.
Laughs in Fedora 39
 0·1 year ago
0·1 year agoThat’s an issue/limitation with the model. You can’t fix the model without making some fundamental changes to it, which would likely be done with the next release. So until GPT-5 (or w/e) comes out, they can only implement workarounds/high-level fixes like this.
 1·1 year ago
1·1 year agoNot exactly a story, but a picture thread on Reddit where a guy posts a photo of his tattoos on his arms, and someone goes “how did you take this picture”, so he posts a selfie showing him balancing a phone on his shoulder, and someone replies “wait how did you take that picture” and then he posts a photo of him taking a photo of him taking a photo… and this continues until he reveals multiple complex camera setups. Such a legendary thread.
Edit: here it is: https://imgur.com/gallery/JThDN

{kind=link}
Over-reliance on proprietary, closed-source products and services from megacorporations.
For instance, it’s really absurd that people in many parts of the world cannot function without WhatsApp, they can’t even imagine a life without it. It seems absurd that Meta literally has them by the balls, and these people can’t do anything about it.
Also the people who base their entire careers on say Adobe or Microsoft products, they’re literally having their lives dictated by one giant corporation, which is very depressing and dystopian.
It’s faster and more memory efficient basically. skim also appears to have been abandoned (no updates in over an year), whereas two_percent is being actively developed.